setTimeout は、指定された時間以降に指定されたコードを実行する JavaScript の API です。ブラウザでも Node.js でも広く使われているのですが、実装はまちまちで、色々と特殊な条件も多く、挙動を完璧に理解している人は少ないと思います。この記事では、そんな setTimeout を可能な限り深堀りしてみようと思います。
先に書いておきますが、ものすごくニッチで細かい話ばかり並びます。突然私が、ただ純粋に setTimeout について調べたくなったので、その結果をまとめただけのものです。普通に開発している人には必要のない情報が多くなるでしょう。この記事は基礎から setTimeout を学ぼう、という方には全然向かないと思います。
また、JavaScript のイベントループについてある程度理解していることを前提とします。その詳しい理解には、@PADAone さんの書かれた「イベントループとプロミスチェーンで学ぶJavaScriptの非同期処理」という本の中の「それぞれのイベントループ」を読んで頂けると良いかと思います。
本文中で、microtask という言葉と (macro)task という言葉を使い分けております。microtask はいわゆる Promise 等で指定される次のイベントループの前に処理されるもの、(macro)task はいわゆる setTimeout 等で指定される次回以降のイベントループで処理されるものです。この記事では主に (macro)task について言及しております。字面が似ているのでご注意ください。
setTimeout のおさらい
setTimeout は JavaScript の言語仕様である ECMAScript では定義されておりません。whatwg で仕様が定義されておりますが、後述しますが仕様通りの実装ではないブラウザが多いです。Node.js でも利用可能です。
基本的には関数を引数と取り、その内容を第 2 引数で指定されたミリ秒以降に実行する API です。第 2 引数を省略するとゼロが指定されたものとして動作します。
const id = setTimeout(() => console.log("3 seconds"), 3000);
確実に 3000 ミリ秒後に発火するわけではありません。だいたい 3000 ミリ秒ちょうどかちょっと後くらいに実行されます。後述しますがスロットリングなどの影響で、たまに長時間実行されずに放置されることもあります。
ブラウザの場合、返り値として timeoutId と呼ばれるゼロより大きい整数値が返ってきます。この id を clearTimeout に渡すことによって、発火前にキャンセルすることが出来ます。
clearTimeout(id);
大抵のブラウザでは timeoutId は連番なので、
for(let i = 1; i < 65536; i++) {
clearTimeout(i);
}
とかやることでページの中にある setTimeout の発火をだいたい止めることが出来ます(本気で止めたい場合は 2 ** 31 - 1 まで回す必要がありますが、まあ大抵は 65535 くらいまで回せば全部止まります)。デバッグ目的でたまに使ったりするテクニックです。
Node.js の場合、返り値としては Timeout クラスが返ってきます。それをそのまま clearTimeout に送ると setTimeout の発火を止められます。
同様の API に setInterval があります。setTimeout は 1 回のみ発火しますが、setInterval は同じミリ秒(以降)間隔で定期的に発火します。setInterval は呼び出した直後は発火しません。また、setInterval も timeoutId を返し、それを clearInverval に渡すことで定期的な発火を止めることが出来ます。なお whatwg の仕様上、timeoutId は setTimeout と setInterval の間で差がないので、setTimeout で返ってきた timeoutId を clearInterval に渡すことで発火を止めることが出来ますし、その逆も可能です。Node.js でも同様の挙動です。しかし可読性の観点からそのようなコードは書かないようにしましょう。
余談ですが、setInterval の clearInterval 忘れはよくあるメモリリークの原因です。個人的にはそれが嫌なので毎回 setTimeout で呼ぶのが好みです。
setTimeout で渡されたコードが実行されるのは、現在の実行コンテキストが終わった次以降のイベントループになります。
setTimeout や setInterval、また Node.js にしかないですが setImmediate に渡されたコードは「(macro)task」として実行されます。microtask ではありませんので、コールバック内から再度これらの関数を登録して即座に呼んでも、イベントループをブロックする心配はありません。
const tick = () => {
setTimeout(tick, 0);
};
tick(); // ブロックしない
queueMicrotask や Promise.resolve().then、また Node.js にしかないですが process.nextTick に渡されたコードは「microtask」として処理されます。コールバック内部で自分自身を登録して即座に呼ぶと、イベントループをブロックしてしまいます。
const tick = () => {
queueMicrotask(tick);
};
tick(); // ブロックする。このコンテキストが終了したら、以降一切他のコードは実行されない。ブラウザなら UI も固まってしまう
なお Node.js の process.nextTick は厳密には microtask とも違うキューで管理されており、他の microtask よりも先に処理されます。microtask が V8 で管理されているのに対して、process.nextTick は Node.js 独自に管理しているタスクキューになります。そもそも process.nextTick は Promise の登場前に必要に応じて作られた機能なのですが、既に Node.js 内部処理でこれを多用しているため、今さら microtask 等に一本化出来ない、という歴史的事情によるものだと聞いております。
ここらへんまでが前提です。では本編行ってみましょう!
ブラウザのみで発生する setTimeout のスロットリング
ブラウザでは、状況に応じてスロットリング(実行の抑制)が行われます。
ページが別のタブの裏に隠れたりした場合
最近のブラウザはタブブラウザが大前提になっておりますが、実行中のウィンドウタブが後ろに隠れたりした場合、setTimeout の間隔が 1000ms 程度に抑制されます。
let last = Date.now();
const tick = () => {
setTimeout(tick, 100);
const elapsedTime = Date.now() - last;
if(elapsedTime < 150) {
console.log("setTimeout fired normally");
} else {
console.log("setTimeout is throttled:", elapsedTime);
}
last = Date.now();
};
tick();
これを実行して、実行したタブを数秒裏側に隠してまた戻すと、実際にスロットリングされている様子を確認することが出来ます。
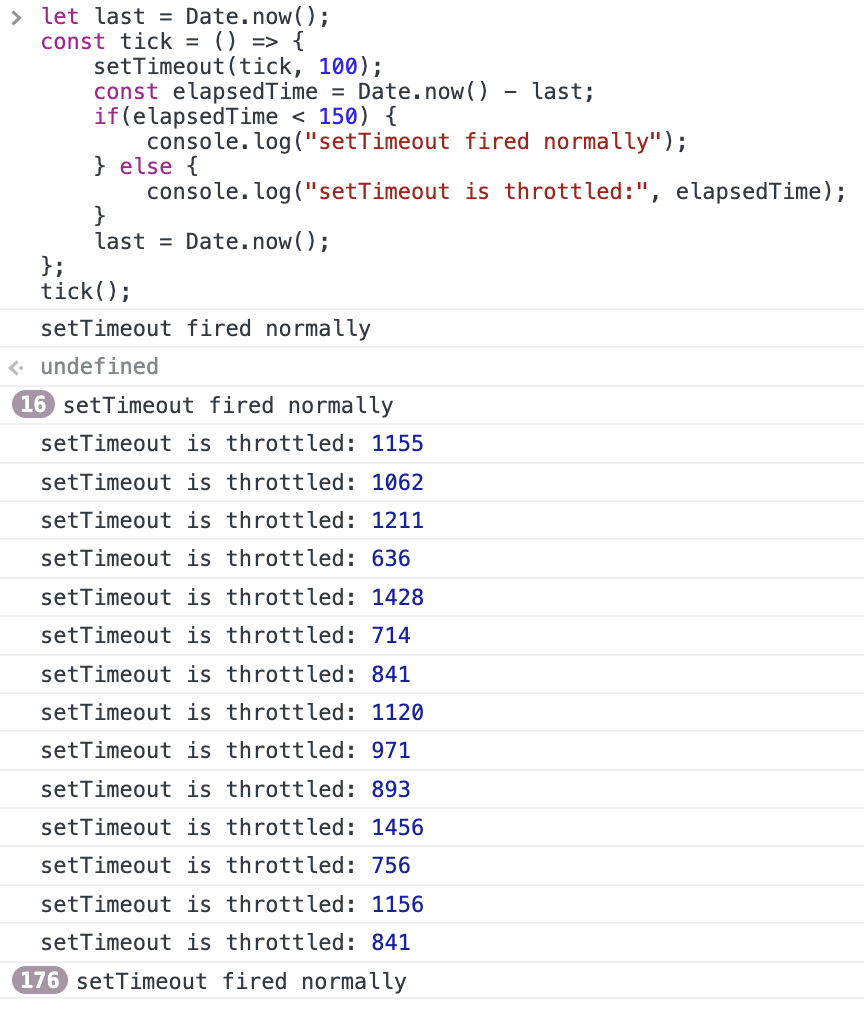
これはアクティブでないアプリケーションの実行を抑制することで、無駄に CPU を使わないようにするための機能です。ゲームなどで FPS 調整をやっている場合には鬼門となる機能ですので、しっかり存在を覚えておきましょう。
なお、requestAnimationFrame でも似たような状況は発生します。ただ最低でも 1 秒に 1 回くらいは実行される setTimeout とは違い、requestAnimationFrame は描画の必要が無い時には一切発火されませんので、定期的な実行を前提にする場合には向いていません。お気をつけください。
極小時間を指定した場合のスロットリング
ブラウザのパフォーマンス改善のため、あまりに短い時間を指定した場合にもスロットリングが行われます。この挙動は仕様にも書かれております。
5. If nesting level is greater than 5, and timeout is less than 4, then set timeout to 4.
簡単に説明すると、setTimeout の中で setTimeout が 5 回より多く呼ばれ、かつ timeout 指定が 4 ミリ秒未満だった場合には、強制的に 4 ミリ秒に設定されます。適当なユーザーコードによって CPU を無駄に消費されないように負荷対策をしているのです。
実験してみましょう。以下のようなコードを書いてみます。
const times = [];
const tick = () => {
times.push(Date.now() - last);
last = Date.now();
if(times.length < 10) {
setTimeout(tick, 0);
} else {
console.log(times);
}
};
let last = Date.now();
setTimeout(tick, 0);
Chrome での結果は以下の通りでした。
[0, 0, 0, 0, 5, 4, 4, 4, 4, 5]
仕様では 6 回目から発生するはずなのですが、4 回目から発生しています。仕様違反ですね!まあ、なにはともあれ数回目からはスロットリングが発生していることが確認出来ました。Firefox でも同様の仕様違反があるように見受けられました。Safari は仕様通りのスロットリングがかかっているようです。
なお Chromium のソースコードを確認したところ、彼らはこれが仕様違反であるのはわかっているようです。個人的にはこの回数の差に意味があるように思えないのですが、しかし既に動いているコードを触りたくない気持ちもよくわかります。たいした違反でもないですしね。
なお最初の数回だけでも 0ms が受け入れられたのは比較的最近で、一昔前は最初の 1 回目からスロットリングが発生しておりました。後述しますが、ブラウザにおいて postMessage を利用することでこのスロットリング制限を抜けることが出来ますが、そもそもスロットリングはユーザーの CPU を過負荷にさせないための機能ですので、あまり多用しないようにしましょう。
巨大な数値の扱い
setTimeout の timeout にとんでもなく大きな値を指定した場合、どのように処理されるかご存知でしょうか?
ブラウザの挙動
ブラウザにおいて大きな値を指定した場合、32bit int に変換して処理されます。わかりやすく言うと、0 以上の数値が指定されたとして
- 0 から 2 ** 31 - 1 までの場合、普通に処理される(最長の timeout 指定は 2 ** 31 - 1 ミリ秒 すなわち 24 日 20 時間 31 分 23.647 秒)
- 2 ** 31 から 2 ** 32 までの場合、32bit int に変換されるとマイナス(もしくはゼロ)になるため、即座に実行される
- 2 ** 32 から 2 ** 32 + 2 ** 31 - 1 までの場合、2 ** 32 で割った余りの数値として処理される
というような感じになります。
setTimeout(() => console.log('3 seconds'), 2 ** 32 + 3000);
なお、この挙動は仕様です。追ってみましょう。まず whatwg における Web API の定義(IDL)を見てみましょう。
long setTimeout(TimerHandler handler, optional long timeout = 0, any... arguments);
このように timeout は long 型で定義されていることがわかります。では、long 型はどのように JavaScript (ECMAScript) に変換されるのか見てみましょう。
An ECMAScript value V is converted to an IDL long value by running the following algorithm:
1. Let x be ? ConvertToInt(V, 32, "signed").
2. Return the IDL long value that represents the same numeric value as x.
The result of converting an IDL long value to an ECMAScript value is a Number that represents the same numeric value as the IDL long value. The Number value will be an integer in the range [−2147483648, 2147483647].
このように、signed 32bit int に変換されることが仕様に明記されております。すなわち、上記の挙動は whatwg の仕様に従ったものであり、それ故に Chrome、Firefox、Safari 全てのブラウザで同じ挙動になります。
Node.js の挙動
Node.js はブラウザの事情に合わせる必要が全く無いので、独自の実装になっています。一応ブラウザに気をつかったのか、2 ** 31 以上の場合は警告を出しつつ timeout を 1 にして即座に実行させるようなコードになっております。その部分の Node.js のソースコードはこちらで確認出来ます。
$ node
Welcome to Node.js v18.12.1.
Type ".help" for more information.
> void setTimeout(() => console.log('immediate'), 2 ** 32 + 3000);
undefined
> (node:84162) TimeoutOverflowWarning: 4294970296 does not fit into a 32-bit signed integer.
Timeout duration was set to 1.
(Use `node --trace-warnings ...` to show where the warning was created)
immediate
ゼロを指定した場合の挙動
setTimeout でゼロを指定した場合、どのような挙動になるのでしょうか。これは実装によって大きく異なります。
Chrome と Firefox の場合
Chrome と Firefox は、イベントループ 1 回ごとに各種類の (macro)task を 1 回ずつ律儀に回しているため、スロットリングが始まるまでの数回位はイベントループにおいて毎回実行されることが確認出来ます。実際に見てみましょう。
JavaScript には setImmediate がありませんので、毎イベントループに確実にタスクをキューイングするために postMessage を利用しています。前述した通りこれは setTimeout の 4ms のスロットリング制限を抜けるための有用なテクニックですが、ユーザー環境に負荷をかける可能性があるのであまり多用しないようにしましょう。
let count = 10;
const timeout = () => {
if(--count) {
setTimeout(timeout, 0);
console.log("timeout");
}
};
onmessage = () => {
if(count) {
postMessage("");
console.log("message");
}
};
setTimeout(timeout, 0);
postMessage("");
上記を実行すると、以下のような結果が得られます。
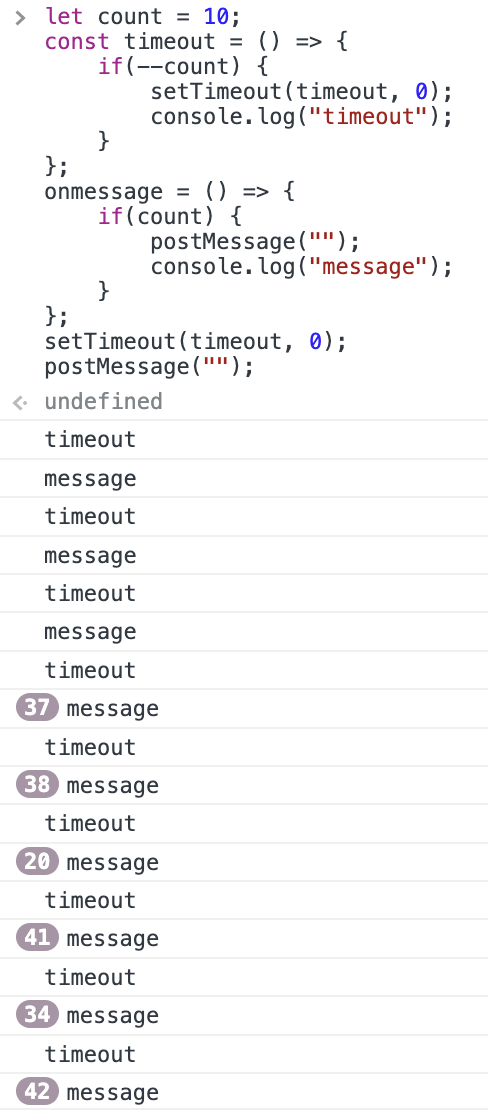
スロットリングが始まるまでは、キレイに timeout と message が並んでいることが確認出来ます。setTimeout をゼロ秒で呼ぶと、毎回のイベントループで実行されているようです。一番下の setTimeout と postMessage を呼ぶ順番を逆にすると結果も反転しますので、同じ (macro)task として優先度なしにキューイングされていることも確認出来ます。
Safari の場合
Safari は結果が大きく異なります。スロットリングが始まる前でも、message が少し多めに呼ばれているようです。
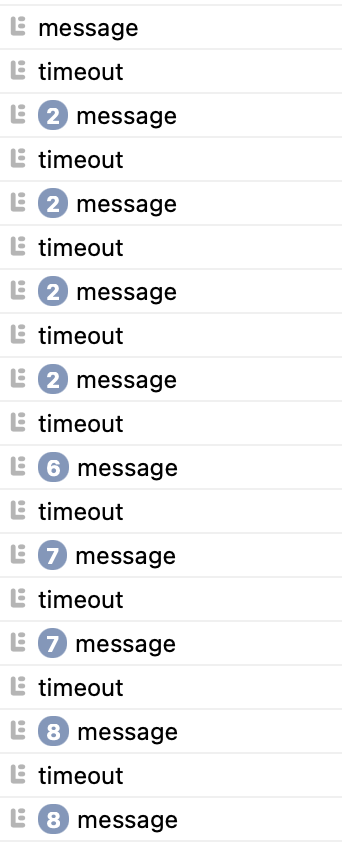
WebKit のコードを少し追ってみたのですが、postMessage は呼ばれた直後に task の enqueue をしているようですが、一方でTimer 系の処理は負荷軽減のための align が入っていたりと色々と手が加わっているようで、そこらが環境と一緒に影響しているように見受けられました。少なくともこれらのコードを読む限り、こちらも postMessage は毎回のイベントループで実行されているのは間違いなさそうです。
Node.js の場合
Node.js の場合は postMessage がない代わりに setImmediate が存在します。これを使ってコードを書き直してみました。
{
let count = 5;
const timeout = () => {
if(--count) {
setTimeout(timeout, 0);
console.log("timeout");
}
};
const immediate = () => {
if(count) {
setImmediate(immediate);
console.log("immediate");
}
};
void setTimeout(timeout, 0);
void setImmediate(immediate);
}
結果は以下の通りです。
immediate
timeout
immediate
immediate
timeout
immediate
immediate
immediate
immediate
timeout
immediate
immediate
immediate
immediate
timeout
immediate
immediate
immediate
immediate
immediate
これは、実は Node.js の setTimeout は timeout に 0ms を指定できない仕様のためです。0ms を指定すると 1ms に設定されます。そして、1ms の間に setImmediate の (macro)task が複数回走るためです。
setImmediate と setTimeout の差は、主にここにあります。覚えておいて損はないかもしれません。
正確なタイミング測定にはどうすればいいのか?
(この節は @bad_at_math さんからの情報提供を元に書いております。ありがとうございます!)
結論から言うと、正確なタイミング計測は諦めるのが一番良い選択肢です。ただ、ビジネス要件として可能な限り正確な測定を求められることがあるかもしれません。そんな時には、 cross-domain Iframe の Web Worker の中で setTimeout を作成する のが最もマシな選択肢になるでしょう。
The most accurate way to schedule a function in a web browser
2020 年 10 月に発表されたこのブログは、何億もの実機で計測したログを元にそう結論づけております。この記事中では Web Worker を生成するコストまで計測していて、とんでもなく参考になりました。記事中でも言及がありますが、Android の成績が一様に悪いのは、iOS と違って低スペックな端末の混入率が非常にたかいことが大きな要因の 1 つになっている点には留意しましょう。
些細な問題点として requestAnimationFrame の実装がおかしかったり(毎フレームコールバック関数を生成しているのは明らかにおかしい)、最も正確に測れるであろう postMessage の計測をしていなかったり(ただしこれは意図的かもしれません。postMessage は非常に端末に負担をかけるので…)、といったことがありますが、結論には全く異論がないので素晴らしい記事です。長いですが興味のある方はぜひ読んでみてください。
他の小ネタ
必ず時間順・登録順に発火するか?
setTimeout が時間順・登録順に発火するかどうかについて気になりますが、仕様的には両者ともに保証されていないと捉えて良いと思います。仕様 5.2 に以下のような記載があり、保証されているように見えます。
Wait until any invocations of this algorithm that had the same global and orderingIdentifier, that started before this one, and whose milliseconds is equal to or less than this one’s, have completed.
しかしこの部分は Run the following steps in parallel: の中にあり、この in parallel の定義を読むと、
To run steps in parallel means those steps are to be run, one after another, at the same time as other logic in the standard (e.g., at the same time as the event loop). This standard does not define the precise mechanism by which this is achieved, be it time-sharing cooperative multitasking, fibers, threads, processes, using different hyperthreads, cores, CPUs, machines, etc.
とあります。すなわち、parallel に実行するための実装は一切規定されていないので、5.2 で保証されているのはあくまでも「前に実行(invocation)されている処理が終わるのを待つ」だけだと捉えられ、結果としてどのような実行順になるのかは仕様で明確に定義されていないと考えて良いと思います(ただ、invocation の定義次第で両者とも保証されていると言ってもよいかもしれません。ここは少し不明瞭です)。
なお、モダンブラウザならびに Node.js の実装では「時間順・(同じ時間の場合は)登録順」の発火になります。しかしその実装に依存したコードを書かないほうが良いでしょう。
文字列による関数の指定
信じられないかもしれませんが、今から 20 年前は、setTimeout のコールバックを文字列で指定するのが一般的でした。HTML のハンドラを文字列で指定しているのと同じような感覚でやっておりました。
setTimeout("console.log('3 seconds')", 3000);
今のブラウザでも利用可能ですが、言うまでもなく、現在では忌むべき書き方です。Node.js では対応すらされておりません。
なお Chrome は、なぜか空文字列を渡すと 0 が返ってきます。
console.log(setTimeout("", 3000)); // => 0
console.log(setTimeout(" ", 3000)); // => non-zero
そもそも setTimeout が 0 を返すのは仕様違反なのですが、実務上なんの問題もない仕様違反ではあります。Chromium のソースコードではこの部分です。コメントには “historically a performance issue” って書いてあるけれど、出典等がないために詳細は全く不明です。これがパフォーマンスに影響を与えるとは思えないのですが、一体どんな事情であったのか気になりますね。
他にも Chrome は eval が実行出来ない環境でこの形式の呼び出しをすると、DevTools に警告を出した上で登録を失敗させ 0 を返してきます。

まあ eval なんて使うなってことですね。
IE で使えない第三引数
IEでは使えないsetTimeoutの第3引数のこと以外は完璧に理解できた! / setTimeout を完璧に理解する https://t.co/ISdXVsj0dt
— Yosuke HASEGAWA (@hasegawayosuke) November 21, 2022
@hasegawayosuke さんから教えていただいたのですが、IE では setTimeout の第三引数(arguments)が使えなかったそうです。なので文字列による関数の指定が流行っていた可能性がある、と。なるほど・・・。
当時でも関数式を使えば自由に引数を渡すことは出来たのですが、2000 年代前半は関数式という考え方がほとんど普及していなかったので、引数が書けないとどうしていいのかわからない人が多かったのかもしれません。
setTimeout(function() { func(arg1, arg2, arg3); }, 1000);
追記:
@kazuho さんによると、そもそも JavaScript 1.1(というものがあることすら知らなかったのですが)までは文字列を渡す方法しか存在しなかったようです。なので文字列を渡す方法が当時の主流だったのは歴史的に当然だったのかもしれません。
Node.js の Promise 対応
setTimeout を素直に Promise 化すると、以下のようなコードになります。これはブラウザでも頻出するコードです。
await new Promise(r => setTimeout(r, 3000)); // wait 3 seconds
Node.js では、promisify を利用して setTimeout を Promise 化して使う用途もあるようです。
Nodeの場合だけ自分は、await util.promisify(setTimeout)(1000) で時間停止させるコード書くこと多い気がする
— 蝉丸ファン (@about_hiroppy) July 26, 2022
本来の setTimeout の構文は promisify とは相容れないのですが、Node.js は util.promisify.custom シンボルを使って例外処理の指定が出来るようで、これを使って対応されているようです。
なお、@yosuke_furukawa さんに教えていただいたのですが、Node.js v15 以降では timers/promises より Promise に対応した setTimeout をそのまま利用出来るようです。
import { setTimeout } from 'timers/promises';
const response = await setTimeout(3000, '3 seconds');
console.log(response);
名前空間は違うものの関数シグネチャが違うのに同じ関数名であることに個人的には危機感を覚えるのですが(後述する WinterCG の文脈ではアウトな気がする)、Promise native な setTimeout が標準で準備されたので、上記のような Promisify の対応は Node.js においては必要なくなっております。promisify の利用は過去の書き方として覚えておきましょう。
setInterval と setTimeout の使い分け
個人的な意見ですが、setInterval を使いたくなることはまずありません。setInterval は発火を止めるために id を保持してそれを後に clearInterval に渡してやる必要がありますが、そのデザインが個人的に気に入りません。そしてそれを忘れてメモリリーク等を作り込んでしまいやすい問題もあり、可能であれば使わない方が良いと個人的に思っています。
では繰り返し処理をどう書くかというと、私は以下のように書いています。
const tick = () => {
if(終了条件) {
return;
}
setTimeout(tick, 100);
実際の処理
};
tick();
この書き方だと tick 内部で終了条件を確認しているため、timeoutId を持ち回すことなく発火を止めることが出来ます。
ここで重要なポイントは、「実際の処理」の前に setTimeout を書くことです。一番最後に setTimeout を書くと、この例だと「処理にかかった実行時間+100ms」に次の tick が呼ばれることになってしまい、処理にかかった実行時間が大きくなればなるほど定期的な実行の誤差が生じます。気をつけてください。
WinterCG による標準化
先日の console.log のブログ記事を書いた際に @petamoriken さんにご指摘を受けたのですが、現在こういった「ECMAScript に入っていないけれど、ほぼ標準になっている便利な API」の標準化作業が WinterCG によって進められています。
JavaScript は様々な理由から、ブラウザと直接の関係がない場所でも使われるようになってきました。Node.js や deno のみならず、Cloudflare の edge computing などにおいても JavaScript は広く使われています。そういった環境で標準化されていない API をサポートするときには各所それぞれが独自の実装をしていました(今回の記事の Node.js の setTimeout 実装がよい例になっていると思います)。この状態が続くと、例えば Node.js で書いたコードが deno や他の非ブラウザー環境で動かなくなる、というような事態が懸念されます。それを防ぐために Cloudflare などが中心となって WinterCG という団体を作って活動しています。
こちらの日本語記事 に詳しいのですが、
WinterCGが独立して、独自の標準APIセットを公開することを意図しているわけではありません。WinterCGから生まれる新しい仕様のアイデアは、まずW3CとWHATWGの既存のワークストリームで検討され、できるだけ幅広い意見の一致を得ることを目指します。
という形で、既存の仕様と協力しながら良い設計を探求していくスタイルのようです。まだ活動が始まったばかりですが、良いアウトプットが出ることを期待しております。なお setTimeout についてはこのように書かれています。
いずれかの環境が標準化APIの定義と異なる場合(例えば、setTimeout()およびsetInterval()のNode.js実装)、その違いを説明した明確な文書が用意されます。このような差異は既存コードとの後方互換性のためにのみ存在する必要があります。